
調査対象と目的を入力すると、複数の検索を並列で回し、集めた情報の出典を検証して、競合比較表・市場概況・顧客ニーズ・SWOT・推奨アクションまでを一気に書き出すリサーチ自動化システムを開発しました。最大の特徴は、レポートのすべての主張に出典番号 [n] が付くことです。
このページでは、何を作ったのか、どう動くのか、そして「AIに調べさせると平気で嘘を書く」という弱点に対して、実装上どこをどう工夫したのかを紹介します。技術的な肝が多いシステムなので、実装の章は厚めに書いています。
効果を示す数値は、中小企業の一次調査を想定したモデルケースに基づく想定値です(特定企業の実測ではありません)。入出力サンプルは架空の2テーマ(「中小企業向けAI業務自動化ツール市場」「健康志向スナック市場」)を使用し、競合名・出典URL・数値はすべて架空のサンプルです。本ポートフォリオのデモは実際のWeb検索・外部AIには接続せず、処理の流れを再現したものです。
何を解決するためのものか
新しい取引先を開拓する。新商品を出す前に市場を見る。新しい領域へ参入するか判断する——。こうした場面では必ず「まず競合と市場を調べる」工程が入ります。ところがこの一次調査が、後回しにされがちで、しかも始めると半日〜1日が消えていきます。
検索して、ページを開いて、読んで、メモして、また別のキーワードで検索して……の反復。終わったころには、どの数字をどこで見たのか分からなくなり、「この情報、出典どこだっけ?」と探し直す。担当者の頭の中だけに調べ方が溜まり、属人化もします。
さらに厄介なのが、AIに「○○市場について調べて」と丸投げしたときの落とし穴です。AIはそれらしい数字や社名をもっともらしく作文してしまうことがあります。出典のない数字を信じて意思決定すれば、判断そのものが崩れます。
このシステムは、「検索で消える半日」を圧縮しつつ、出典のない主張は最初から出さないという形で、その落とし穴をふさぐことを狙ったものです。
どんなシステムか
利用者がやることは、調査テーマと目的を入れて待つだけです。裏側では、AIエージェントが複数の検索を並列で回し、集めた情報の出典を検証してから、構造化レポートに統合します。
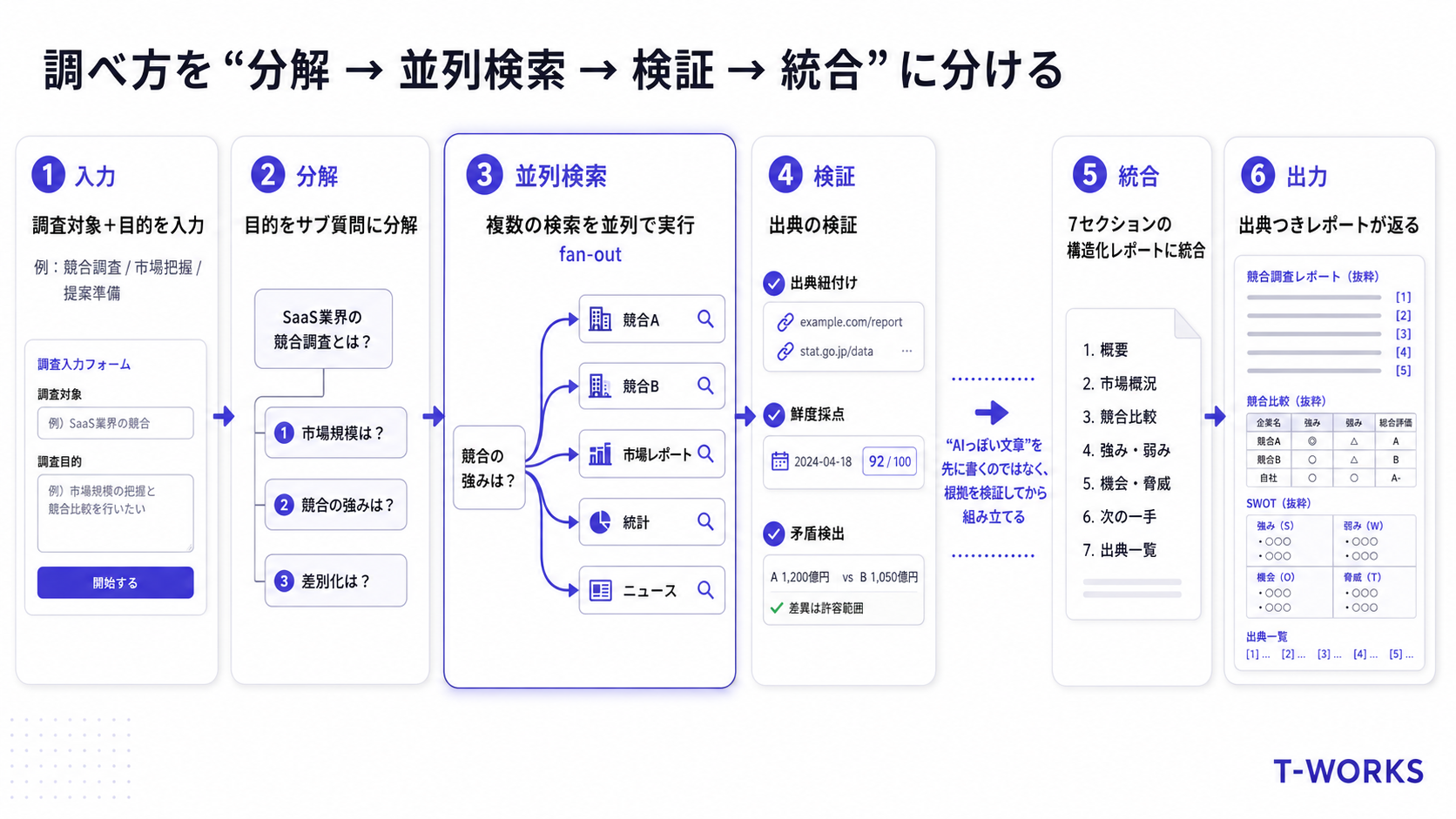
調べ方の中身は、おおまかに次の流れです。
- 目的をサブ質問に分解 — 「競合比較がしたい」「市場規模が知りたい」といった目的を、調べるべき小さな問いに割り直す
- 複数角度で並列検索(fan-out) — 分解した問いごとに、複数の検索を同時に走らせて情報を集める
- 出典の検証 — 集めた主張それぞれに出典を紐づけ、公開日で鮮度を採点し、矛盾する主張を検出する
- 構造化レポートへ統合 — 7つのセクション(サマリー/競合比較表/市場概況/顧客ニーズ/SWOT/推奨アクション/出典リスト)に固定フォーマットで書き出す
「AIっぽい調査レポートを書かせる」のではなく、根拠を一つずつ検証してから組み立てることに振り切っています。出てくるレポートは、どの一文も「出典リストのどれに基づくか」を [n] でたどれます。
入力と出力(実際のサンプル)
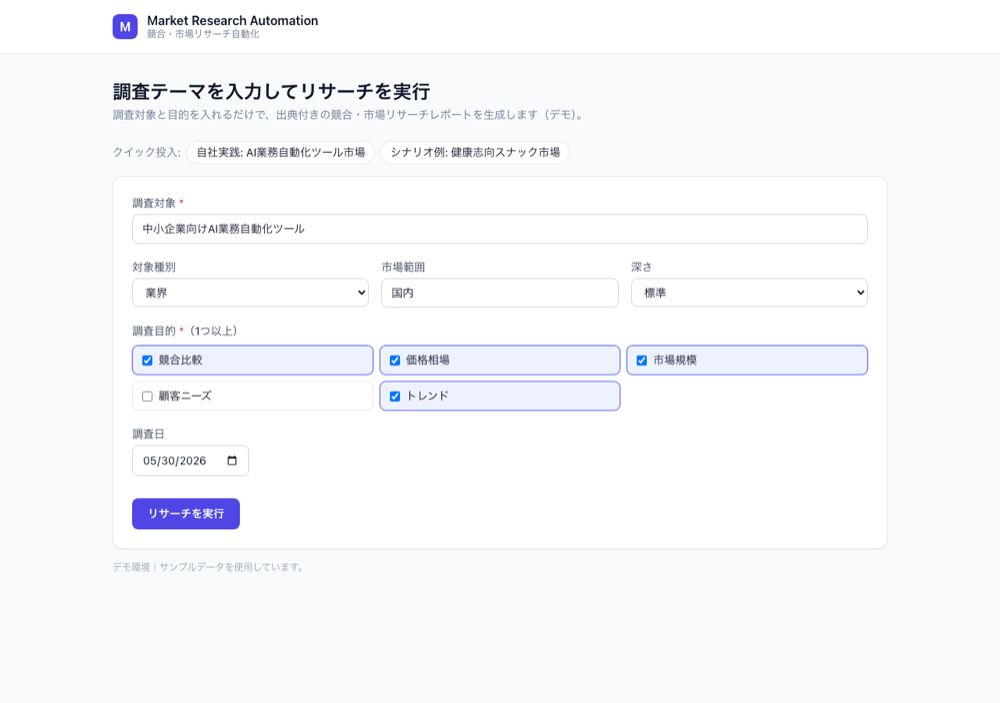
入力(調査条件を入れるだけ)
入力画面はシンプルです。調査対象・調査の目的(競合比較/市場規模/顧客ニーズなど)・範囲(国内/グローバル)・深さ・調査日を指定するだけ。よく使うテーマはワンクリックで投入できるようにしています。
出力(出典つきの構造化レポート)
実行すると、数十秒で構造化レポートが返ります。冒頭にはメトリクスのバッジ(競合数・参照ソース数・出典付き主張の割合)と、検証結果のバナーが出ます。下は「中小企業向けAI業務自動化ツール市場」を調べたサンプルの上部です。
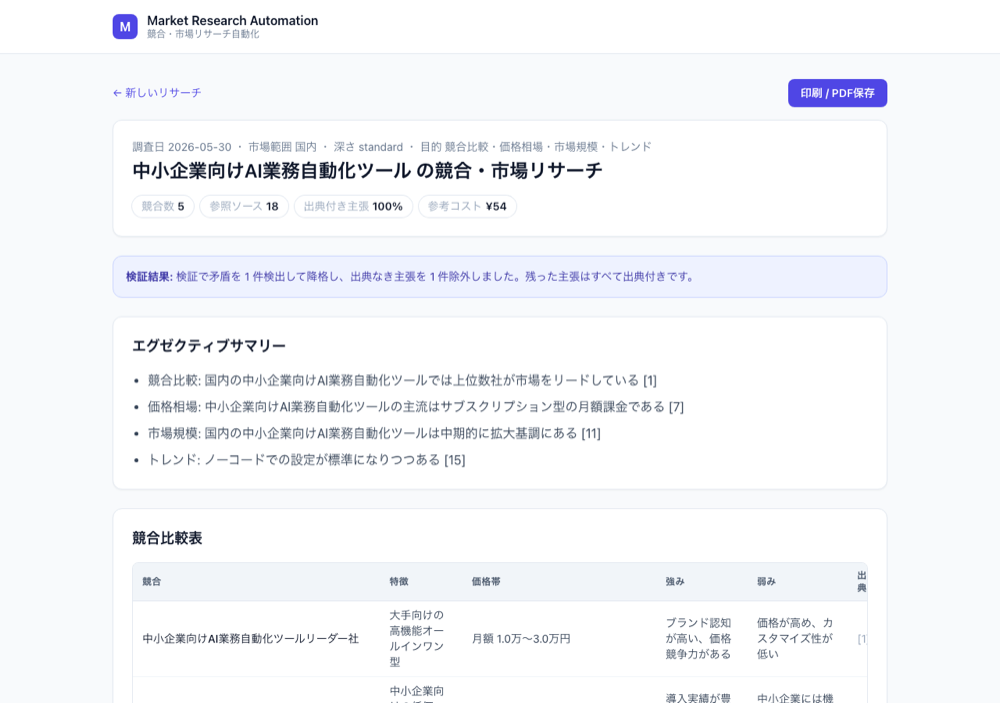
注目してほしいのは、各セクションの一文ごとに [n] という出典番号が付いている点です。たとえば市場概況やSWOTの各行は、末尾の「出典リスト」(URL・参照日・一次情報か二次情報か・信頼度バー)と対応しています。出典付き主張の割合は 100%。レポートの中で「根拠が示せない一文」は一つもありません。

同じシステムに、まったく別の業界——地方の食品メーカーが新商品を出す前に調べる「健康志向スナック市場」を入れても、同じ構造のレポートが返ります。業界が変わってもフォーマットと検証の基準は一定です。

実装で工夫したこと
ここがこのシステムの肝です。AIリサーチの一番こわいところは「もっともらしいウソ」です。それを構造でふさぐために、設計の中心に置いたのは、判断はAIに、検証は決まった処理にという役割分担です。

1. 一つの目的を複数の検索に分解して、並列で走らせる(fan-out)
「競合を比較したい」という一つの依頼を、そのまま一回検索しても良い結果は出ません。このシステムは目的をサブ質問に分解し、問いごとに複数の検索を**並列(fan-out)**で走らせます。一人で順番に調べるのではなく、複数の調査担当に同時に手分けさせるイメージです。角度の違う検索を同時にかけることで、一方向の検索では拾えない情報まで網にかかります。サブ質問への分解は、後段の検証で「どの問いに対する答えなのか」を追跡する手がかりにもなります。
2. 出典のない主張は、レポートに出さない(構造的に不可能にする)
このシステムでは、一つひとつの主張(claim)は必ず出典を伴う決まりにしています。出典が取れなかった主張は、レポートを組み立てる前の段階で自動的に除外します。レポートを描画する処理側にも「出典 [n] の付かない主張行は出力しない」という不変条件を持たせ、二重にふさいでいます。実際のサンプルでは、出典の取れない草案主張を1件、生成前に自動で落とし、「検証: 出典なき主張を1件除外」と明示しています。
重要なのは、この「出典があるか」の判定ロジックを1か所に集約したことです。レポートの描画・後述の検証フック・テストが、それぞれ別々の基準を持つと、片方は通って片方は止まる、といった食い違いが起きます。判定を一本化することで、「画面に出るレポート」と「機械が検査する基準」が必ず一致します。
3. 矛盾は「捨てる」のではなく「降格して見せる」
調べていくと、相反する情報にぶつかります。たとえば市場規模について「拡大基調」と「頭打ち・縮小懸念」の両方の主張が出てくる、といったケースです。安易なシステムは片方を黙って捨ててしまいますが、それでは「都合のいい情報だけ残った」レポートになりかねません。
このシステムは矛盾を検出すると、**信頼度の低い側を降格(demoted)**したうえで、その事実をレポートに残します。サンプルでは、降格した主張をSWOTの「脅威」欄に「(検証で降格・要確認)」として可視化し、「検証で1件の矛盾を検出」と明示しています。AIリサーチの最大の弱点である「もっともらしい誤情報」に対して、隠さず・見える形で対処する——ここが技術的に一番こだわった部分です。
4. 同じ入力なら、毎回まったく同じレポートが出る(決定性)
レポートに使う乱数は、**入力から作った一つの種(seed)**だけから生やしています。グローバルな乱数や「実行した時刻」といった、入力の外にある要素を一切混ぜません。目的の並び順すら入力の一部として種に含め、「同じ入力 → 同じ出力」を厳密にしています。これにより、サンプルやスクリーンショットの再現性が保証され、記事の数字も「たまたまそう出た値」ではなくなります。
5. 出力後に、システム自身が「出典の抜け」を検査する
生成したレポートを、検証用の処理(フック)が機械的に再チェックします。すべての主張行に出典 [n] が付いているか、参照日や調査日のスタンプが揃っているかを検査し、出典のない主張が1件でもあれば終了コード1で失敗します。実際の実行ログがこちらです。
$ market-research-check samples/expected-output/ai-tools.md
想定コスト記録: 競合数: 5 / 参照ソース数: 18 / 出典付き主張の割合: 100% / 想定コスト: ¥54
検証フック: OK(主張 全18件すべて出典付き / 出典 18 件)
(終了コード: 0)
「AIの出力を人が全部見なくても、出典の抜けを機械が止める」——この訴求を、実際に動くチェックとして実装しています。
6. 外部API・課金は構造的に起こらないようにしてある
検索・取得・主張抽出といった外部に当たる部分は、共通のインターフェース(アダプタ)の裏に隔離しています。本ポートフォリオのデモでは既定で外部に接続しないアダプタを使い、実際のWeb検索・外部AIにはつなぎません。実接続するアダプタは差し替えできる設計ですが、誤って従量課金が発生しないよう、実行しようとすると例外で停止するガードを入れてあります。外部依存を1点に閉じ込めたことで、「端から端まで動くのに費用ゼロ」を担保しています。
7. 品質をテストと画面レビューの両方で固めている
分解・検証(矛盾降格・出典除外)・信頼度の採点・整形(Markdown/HTML)といったローカルの決定的処理は、自動テストで品質を固めています(現在 76 件のテストが通過)。外部に当たる部分はモックに差し替えてテストできる構成にしてあり、課金を発生させずに挙動を検証できます。
加えて、Web画面は実際にレンダリングして見た目のレビューも回しました。初回レビューでは「競合比較表のセルが折り返しで崩れる」「SWOTの脅威セルの文字が背景に埋もれて読みにくい」という指摘が出て、テーブルに最小幅と横スクロールを入れ、SWOTの配色を強化して作り直しました。画面を実際に出してみて初めて気づける崩れで、コードを読むだけでは拾えない種類の品質です。
成果(想定モデルケース)
項目 | 導入前(Before) | 導入後(After) |
|---|---|---|
競合・市場の一次調査 | 検索→精読→メモの反復で半日〜1日 | テーマ入力→数十秒で構造化レポート+レビュー数十分 |
出典の整理 | 抜け漏れ・出典不明が起きやすい | 全主張に出典 |
情報の鮮度・矛盾 | 古い情報や矛盾に気づきにくい | 公開日で鮮度を採点し、矛盾を検出して降格・可視化 |
もっともらしい誤情報 | 気づかず信じてしまう恐れ | 出典なき主張はレポート生成前に自動除外 |
出力フォーマット | 人によってバラバラ | 7セクション固定(印刷でPDF化も可能) |
再現性 | 調べ方が属人化 | 同じ入力なら毎回同じレポート |
後回しになりがちな調査ほど、効果が積み重なります。
上記は「1テーマ・競合5社・参照ソース十数件」を想定したモデルケースの効果です。手作業時間は中小企業で一般的な想定値であり、特定企業の実測ではありません。本デモは外部API(Web検索・AI)に接続しない構成のため処理は一瞬ですが、実接続した場合の処理時間・コストは検索量やAIの利用量によって変わります(現時点では未実測のため掲載していません)。
データの扱い
本ポートフォリオの入出力サンプルは、すべて架空の2テーマ(中小企業向けAI業務自動化ツール市場/健康志向スナック市場)です。競合名は「○○リーダー社」のようなテンプレートで生成しており、出典URLは検証用のダミードメインを使用しています。実在の社名・個人名・取引先・金額・投資商材は一切含みません。「お客様の声」のような証言も載せていません。デモは外部に一切接続せず、処理の流れを再現したものです。実運用では、調べる範囲・許可するソース・出力フォーマットを御社のルールに合わせて設定できます。
御社の競合・市場調査でも
このシステムは、調べる目的(競合比較/市場規模/顧客ニーズなど)・対象業界・出力フォーマットを、御社の使い方に合わせて形を変えられます。新規開拓前の競合チェック、新商品投入前の市場確認、定期的な競合ウォッチの自動化——いずれも、既存の業務の中に「乗せる」形で組み込めます。
「調べ物に半日取られている」「AIに調べさせたいが、根拠のない数字を信じるのが不安」——そんな課題があれば、お気軽にご相談ください。実運用に向けた実装支援・業務改善という形でお手伝いできます。