
社内規程・マニュアル・FAQを登録しておくと、「経費精算の申請期限は?」のような自然な質問に、出典付きで答える検索ボットを開発しました。RAG(検索拡張生成)という、社内文書を根拠にして回答を組み立てる仕組みを使っています。
このページでは、何を作ったのか、どう動くのか、そして実装上どこを工夫したのかを紹介します。
効果を示す数値は、中小企業の社内問い合わせ業務を想定したモデルケースに基づく想定値です(特定企業の実測ではありません)。デモの検索精度は、外部APIに接続せずローカルで決定的に再現した近似版による参考値で、本番は埋め込みモデルへ差し替える設計です。入出力サンプルには架空の「株式会社みなとデジタル」の社内文書を使用しています。
何を解決するためのものか
「これってどこに書いてあったっけ?」——社内でよく聞く声です。
経費精算のルール、有給の申請方法、リモートワークの規程、VPNの設定手順。どれも社内のどこかに書いてあるはずなのに、フォルダを横断して探し、見つからなければ総務やシステム担当に都度確認する。聞かれる側も、そのたびに手を止めて回答します。この「探す・聞く・答える」が積み重なると、見えない時間がじわじわと消えていきます。
このシステムは、その手間を「文書に直接質問する」体験に置き換えることを狙ったものです。社員は質問するだけ、答えは出典(どの文書のどこに書いてあるか)付きで返るので、必要なら一次文書まで自分で確認できます。
どんなシステムか
ポイントは、AIに「それっぽい答え」を作文させるのではなく、登録した社内文書の中から根拠になる箇所を探し、その箇所に基づいて回答することです。これがRAG(検索拡張生成)の考え方です。
利用者の体験はシンプルです。
- まず、社内文書を登録しておく(後述のとおり Google Drive / Notion / 社内ファイルサーバの文書をソースにできる想定)
- 社員はチャット画面で普通の日本語で質問する
- システムが関連する箇所を検索し、出典付きの回答を返す
- 根拠が見つからない質問には、推測で埋めず**「分かりません」と返す**
要約や雑談ができるツールは数多くありますが、業務で本当に必要なのは「答えの根拠がたどれること」と「無いものは無いと言ってくれること」です。このシステムはそこに振り切っています。
入力と出力(実際のサンプル)
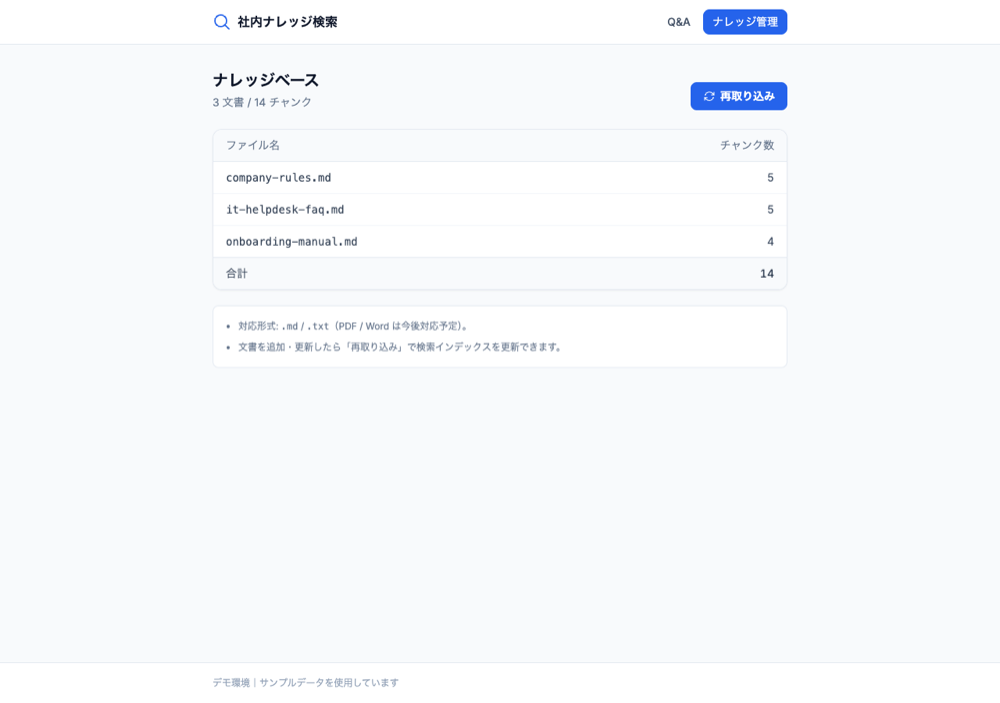
まず、社内文書を登録します。下の画面では、架空の社内規程・IT FAQ・入社オンボーディング手順の3文書を取り込み、検索しやすい単位(チャンク)に分割して管理しています。文書を更新したら再取り込みするだけで、最新の内容が検索対象になります。
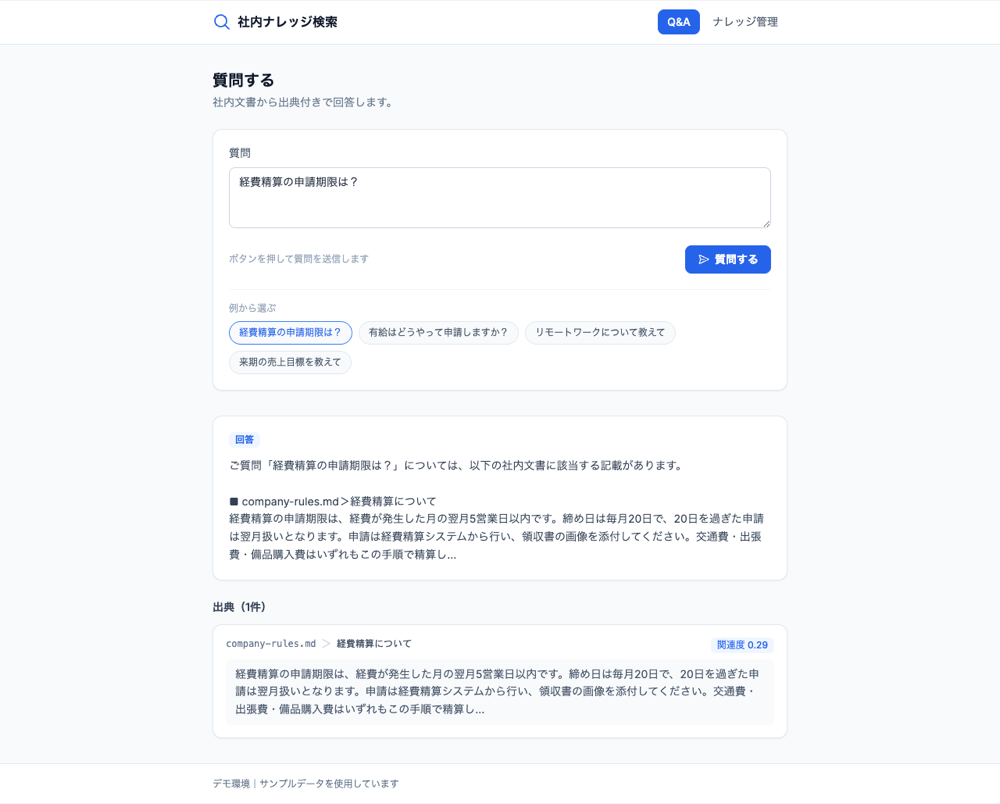
登録が済めば、あとは質問するだけです。「経費精算の申請期限は?」と聞くと、回答とともに出典カード(どのファイルのどの見出しから引いたか、抜粋、関連度のバッジ)が表示されます。
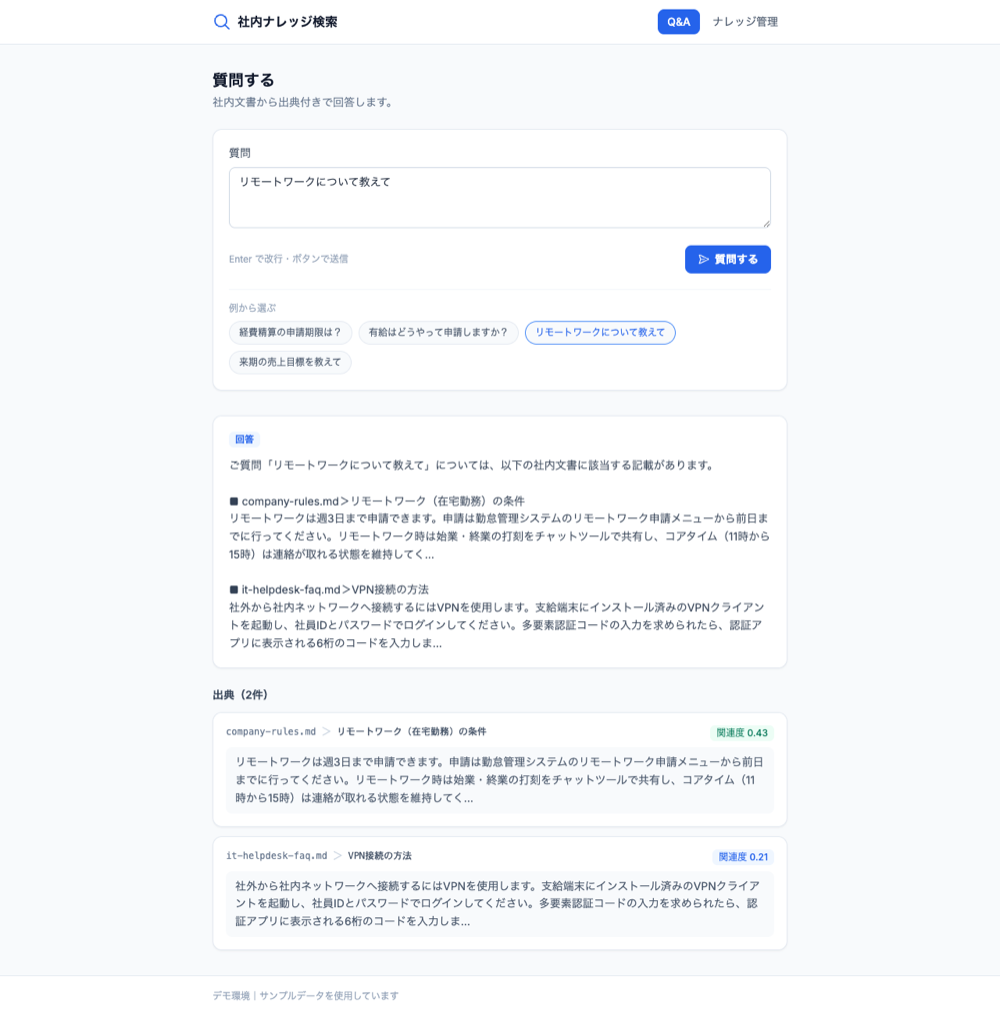
質問によっては、答えが複数の文書にまたがることもあります。たとえば「リモートワークについて教えて」のように横断的な質問では、関連する複数の文書を出典として提示し、関連度の高さで色分けして示します。
一方で、登録された文書のどこにも根拠がない質問——たとえば「来期の売上目標を教えて」——には、もっともらしい数字をでっち上げず、「該当する社内文書が見つかりませんでした」と正直に返します。
質問: 来期の売上目標を教えて
→ 関連する社内文書が見つかりませんでした(最も近い文書でも関連度 0.00 < しきい値 0.12)。
推測での回答は行いません。
スマートフォンからも同じように使えます。
実装で工夫したこと
ここがこのシステムの肝です。RAGは「それっぽく動く」だけなら難しくありませんが、業務で信頼して使うには、根拠の確かさとわからないことを正直に出すことを作り込む必要があります。
1. 「もっともらしい嘘」を出さない(出典の自己点検)
RAGで一番こわいのは、AIが文書にない内容を自信たっぷりに答えてしまうこと(ハルシネーション)です。このシステムでは、回答に必ず検索で取得した文書の抜粋を根拠として埋め込み、さらにその出典が本当に取り込み済みの文書由来かを、専用の検査処理(フック)が機械的にチェックします。
$ python -m faq_rag.hooks.check_grounding
grounding チェック: 違反なし(pass)
(終了コード: 0)
出典のファイル名がインデックスに実在し、抜粋が元の文書の一部であることを検証する仕組みで、捏造した出典が混じっていれば異常終了して弾きます。「AIの回答が根拠に基づくか」を人手のレビューなしで担保することを狙っています。
2. 「分からない」を正直に出す(しきい値の校正)
根拠がない質問に対して、無理に答えを作らないことを設計の中心に据えています。検索で得た関連度が一定のしきい値を下回ったら、出典を出さず「分かりません」と返します。
このしきい値は勘で決め打つのではなく、サンプルの問答で実測して校正しました。正答できる質問の関連度(およそ 0.18〜0.43)と、該当文書がない質問の関連度(0.00)を測り、両者をきれいに分離する 0.12 を採用しています。しきい値は設定で外出しにしてあり、文書量や運用に合わせて調整できます。「無関係な質問は確実に弾く」ことを境界条件のテストで固定しました。
3. 日本語をそのまま検索できるようにする
文書検索の標準的な部品は英語向け(単語が空白で区切られている前提)に作られていることが多く、日本語をそのまま入れると精度が出ません。形態素解析の追加ライブラリを入れる手もありますが、導入のハードルが上がります。そこでこのデモでは、文字単位のN-gramで日本語を扱う方式を採用し、追加インストールなしで日本語の質問が引けるようにしました。本番では精度の高い埋め込みモデルに差し替えられる構成です。
4. 後から本番仕様に差し替えられる構造
「検索する部分」と「回答を組み立てる部分」を、決定的に動くローカル処理で再現できるように設計しました。同じ質問には必ず同じ回答が返るため、デモや検証の再現性が高く、外部APIの課金もかかりません。そのうえで、本番では検索を高精度な埋め込みモデルに、回答生成を生成AIに、それぞれ差し替え(アダプタ)で移行できる境界を引いてあります。「決まった処理で確実に動く土台」と「AIに任せる部分」を分けておくことで、検証のしやすさと将来の拡張性を両立しています。
5. 品質をテストで担保している
チャンク化・検索・しきい値判定・回答合成・出典の自己点検といった処理は、自動テストで品質を固めています(現在 51 件のテストが通過)。外部APIに毎回つながなくても挙動を検証できる構成にしてあり、誰がいつ実行しても同じ結果を確認できます。
成果(想定モデルケース)
項目 | 導入前(Before) | 導入後(After) |
|---|---|---|
資料を探す | フォルダを横断して手作業で探す | 質問するだけで出典付き回答が返る |
規程の問い合わせ | 総務・システム担当に都度確認、回答待ちが発生 | 社員が自己解決、対応件数が減る |
回答の正確性 | 人の記憶・解釈でばらつく | 一次文書(出典)に基づき検証できる |
該当情報がない時 | 探し続けて時間を消費 | 「分かりません」と即返して無駄打ちを防ぐ |
社員数や社内文書が多い組織ほど、積み重なる効果は大きくなります。
上記は中小企業の社内問い合わせ業務を想定したモデルケースの効果です。実際の効果は文書量・問い合わせ件数・文書の整備状況によって変わります。数値は想定値で、導入時は試験運用で実測する前提です。
データの扱い
社内文書を端末内で処理する構成にもできるため、規程やマニュアルを外部に出さずに運用することも可能です。サンプルはすべて架空の「株式会社みなとデジタル」のダミー文書で、実在の社名・個人名・金額・取引先は含みません。本番ではアクセス権に応じて見せる回答を制御するなど、社内のセキュリティ要件に合わせた作り込みもできます。
御社の社内ナレッジでも
このシステムは特定のツールに縛られず、御社がいま使っている Google Drive / Notion / 社内ファイルサーバの文書をソースにできます。新しいツールへの全面移行を強制せず、既存の運用に「乗せる」形で導入できます。PDFやWordの取り込み、文書更新の自動同期といった拡張も、必要に応じて段階的に進められます。
「社内の問い合わせ対応を軽くしたい」「答えの根拠がたどれる形で社内文書を活かしたい」——そんな課題があれば、無料相談でお聞かせください。